手机百家家乐app下载 32B特殊671B!M-A-P全开源数学定理诠释模子OProver,五项评测三项第一

OProver团队 投稿
量子位 | 公众号 QbitAI
情势化定理诠释,一直是LLM公认最严苛的推理试金石,每一步推导都必须通过Lean 4内核的机器考据。
近两年,开源社区在MiniF2F、PutnamBench等benchmark上的收货执续上涨,但增长旅途越来越趋同:扩模子、扩数据、部署阶段类似检索和多轮修正。
一个关键问题永恒存在,检索信号、编译器反映和失败开发,大多只在部署时动作外部历程接入,模子在历练阶段并莫得系统学习奈何行使这些信号,酿成了历练与部署之间的“政策错位”。
为搪塞这一挑战,M-A-P开源社区与南京大学等团队提倡OProver——
一个将检索增强、编译器反映与多轮开发告成内化到历练政策中的Lean 4定理诠释框架。

在五个Lean 4 whole-proof prover评测中,OProver-32B获得三项第一、两项第二:
MiniF2F(93.3)、ProverBench(58.2)、PutnamBench(11.3)向上 LongCat-Flash-Prover w/ TIR,并在沿途五项评测中特殊 671B 的 DeepSeek-Prover-V2。
讨论团队同步开源1.76M条情势化叙述、6.80M编译器考据诠释的OProofs语料库,以及8B/32B共7个模子权重。
代码、权重与历练剧本已全面开源。
政策错位:历练与部署之间的中枢矛盾
连年来的Lean 4 prover系统(Goedel-Prover-V2、DeepSeek-Prover-V2、Kimina-Prover 等)在MiniF2F上还是把Pass@32推到较高水平,同期也有责任开动引入检索、编译器反映或self-correction。
问题在于,这些信号主要动作部署阶段的增强历程,接在已资格练好的prover外部,而非从历练阶段就被纳入学习野心。
这就酿成了错位:
历练阶段,模子主要看到明晰的theorem→verified proof监督对
部署阶段,系统却把检索到的联系诠释、上一轮失败尝试和Lean编译器反映再行提供给模子,条目进行多轮开发
OProver的中枢念念路,是让历练野心与部署时的诠释过程对都:让模子在历练阶段就学习奈何现实agentic refinement loop,把多轮修正、检索联系诠释和编译器反映动作历练政策的一部分,而非部署阶段的外部包装。
轻量、可端到端历练
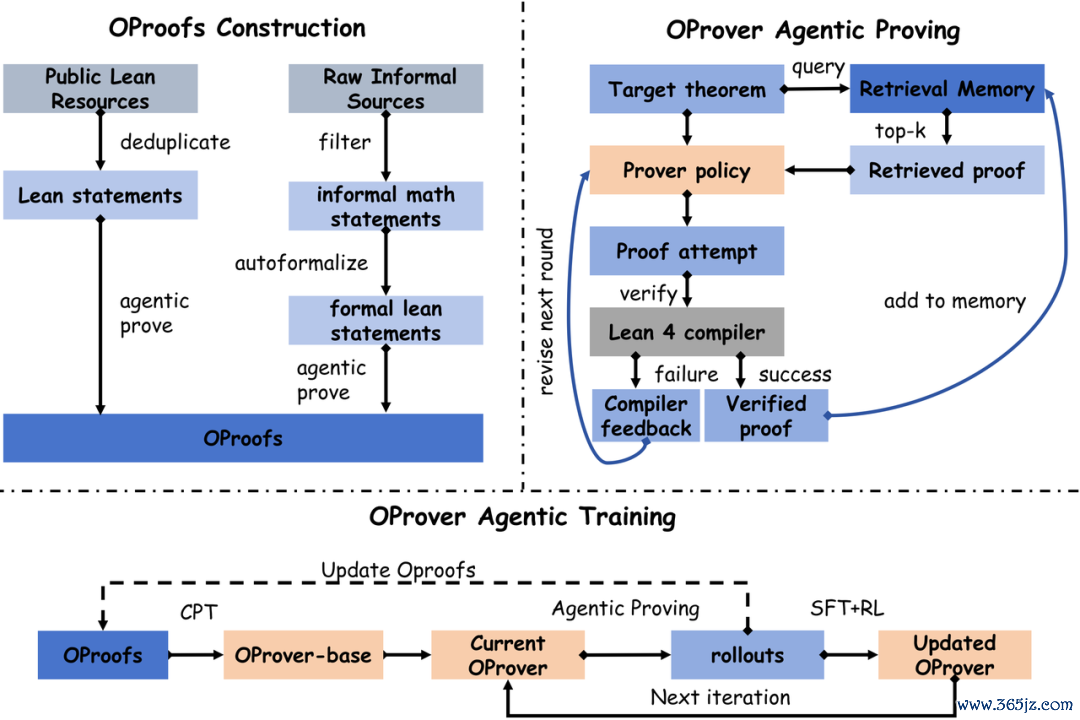
部署阶段:有限轮次开发轮回
OProver把定理诠释建模为一个有限轮次的开发轮回。
政策基于野心情势化叙述、检索哀吊库中的top-k个编译器考据诠释、上一轮诠释尝试和Lean 4编译器复返的会诊信息,生成下一次诠释尝试。任性一轮通过,整条trajectory即视为告捷。
历练阶段:两阶段历练
执续预历练(CPT):在约65B token的混杂语料上预历练,其中约30%来自OProofs的Lean 4数据,20%为代码数据(OpenCoder),40%为数学语料(Nemotron-Math-4-Plus),10%为长CoT数据
迭代后历练:轮流进行agentic proving rollout、SFT(基于round-level开发样本)和RL(基于GSPO算法与贫寒集)
关键设想在于:检索效果、失败尝试和编译器反映不再仅仅部署阶段临时接入的外部历程,而是被纳入模子要学习的诠释政策。
数据与模子的协同进化
OProofs语料库与prover政策在迭代中相互促进。
每轮迭代中,现时prover在题库上生成的新考据诠释被加入OProofs并索引进检索哀吊库;
开发trajectory成为下一轮SFT历练样本;尚未管束的”贫寒组”为下一轮 RL 提供历练信号。
数据、历练与政策,手机百家家乐app下载酿成执续演化的闭环。
OProofs:面向agentic prover的Lean 4语料
讨论团队同步构建并开源了OProofs,包含约1.76M条情势化叙述、6.80M条编译器考据诠释。
其中4.29M条诠释保留了检索到的联系诠释高下文,859K条样本包含此前失败尝试的Lean编译器反映。模子不单看到”最终正确诠释是什么”,也能学习”诠释失败后,奈何行使检索效果和编译器反映不竭开发”。
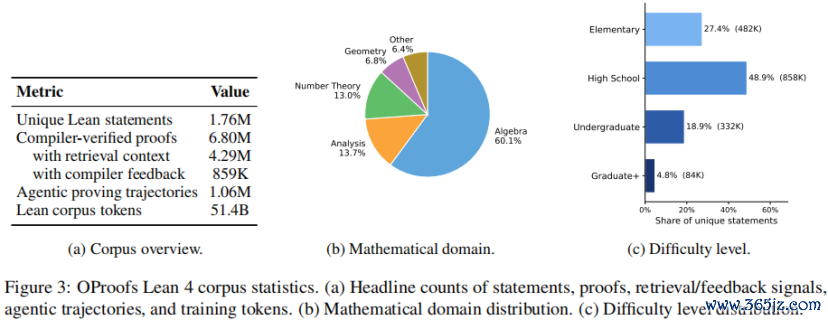
OProofs由两条构建分支构成。
1、公开资源再诠释
以NuminaMath-LEAN、Lean-Workbook、Leanabell-Prover-FormalStmt等公开Lean资源为起初,清洗去重后通过agentic proving再行生成并考据诠释,同期采集检索高下文、失败尝试和开发轨迹。
2、当然言语到情势化
从Common Crawl和GitHub挖掘数学叙述,用CriticLean自动情势化为Lean 4,再通过agentic proving历程生成并考据诠释。
从秘密限度看,OProofs横跨多个数学见解:代数60.1%、分析13.7%、数论13.0%、几何6.8%。难度踱步以 elementary(27.4%)和high-school(48.9%)层级为主,同期包含18.9%的本科水柔和4.8%的讨论生水平问题。
五项评测三项第一、两项第二
讨论团队在MiniF2F、MathOlympiad、ProofNet、ProverBench、PutnamBench五个Lean 4 benchmark上评估,默许报恩Pass@32,基于n=64条沉寂multi-round rollouts的无偏臆测。
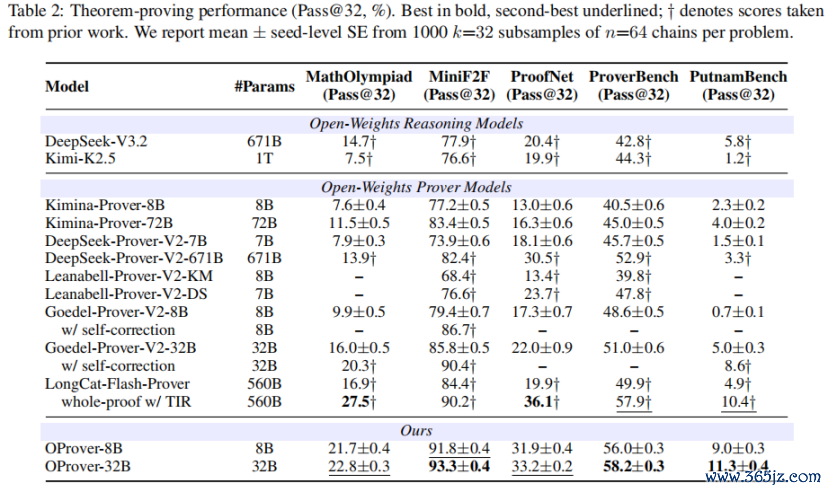
在open-weight whole-proof prover限度内,OProver-32B有三项关键论断:
1、32B全面特殊671B
OProver-32B在沿途五项评测中特殊 DeepSeek-Prover-V2(671B),在 MiniF2F(93.3)、ProverBench(58.2)、PutnamBench(11.3)上同期向上LongCat-Flash-Prover w/ TIR(560B)。
2、8B打平32B
OProver-8B在五个benchmark上沿途特殊Goedel-Prover-V2-32B,参数目少4倍。
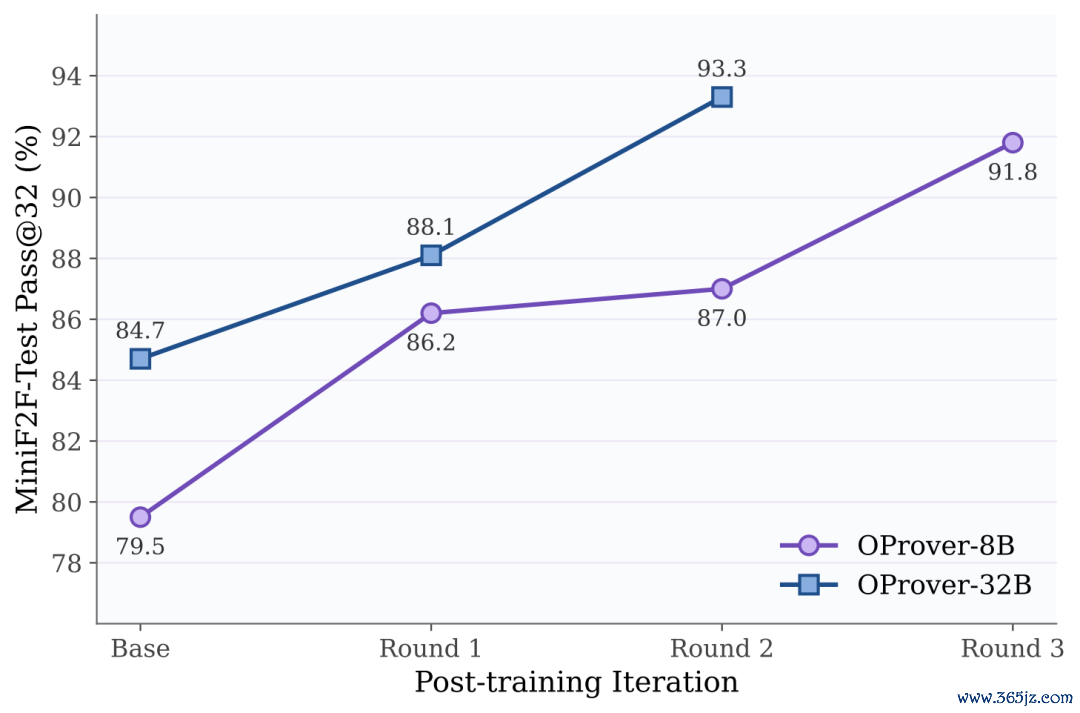
3、迭代后历练执续增益
MiniF2F-Test 上,OProver-8B从79.5进步至91.8(+12.3),OProver-32B从84.7进步至93.3(+8.6)。
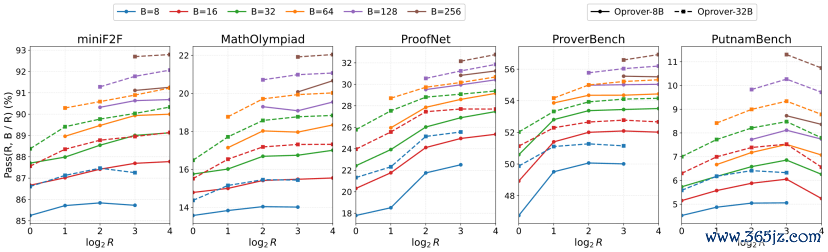
消融实验:检索与编译器反映协同孝顺
移除多轮compiler feedback会导致最大幅度下落:OProver-32B在PutnamBench从11.3降至7.0,在ProofNet从33.2 降至25.8。
进一步移除检索后,性能不竭下落至5.9和24.7。
这证据进步并非来自浅近的best-of-N采样,而是来自检索增强的诠释生成与编译器反映指点的多轮开发之间的协同。
其中,Lean 编译器反映提供主要开发信号;检索高下文提供联系诠释结构和可参考的诠释片断。
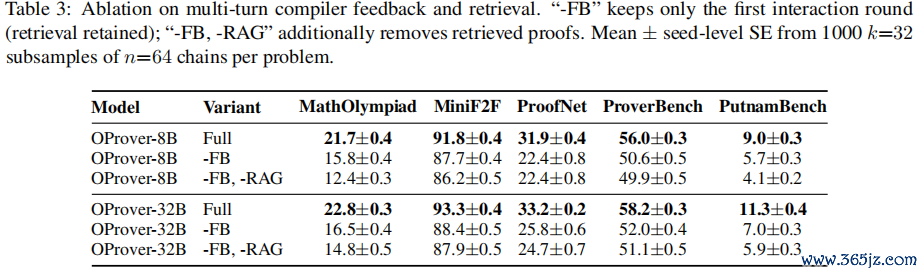
测试时膨胀:更多推理预算踏实滚动
跟着推理预算从8加多到256,OProver-32B在五个benchmark上均呈踏实进步:MiniF2F从87.5至92.8,MathOlympiad从15.5至22.0,ProofNet从25.6至32.8,ProverBench从51.3至56.9,PutnamBench从6.4至11.3。
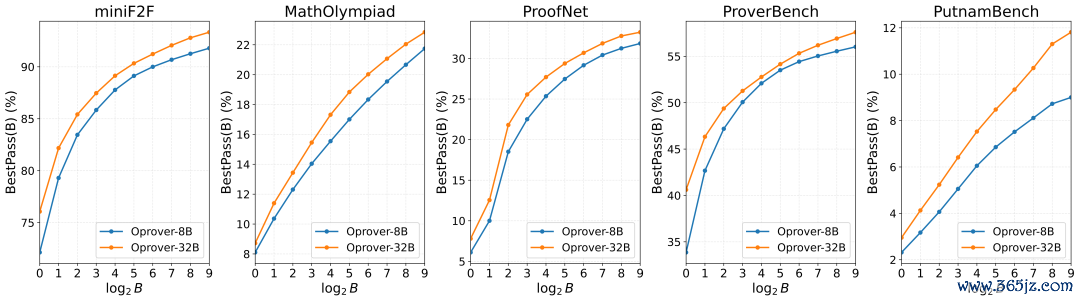
最优预算分拨与benchmark难度联系:无数benchmark更偏向加多refinement深度,而PutnamBench这类低告捷率贫寒需在开发深度与并行探索之间获得均衡。
开源与发布
讨论团队同步开源了OProver的模子、数据与历练代码,秘密不同历练阶段checkpoint、OProofs语料和历练pipeline。
• m-a-p/OProver-32B / OProver-8B — 最终模子
• m-a-p/OProver-32B-Base / Round1 — 32B 各阶段 checkpoint
• m-a-p/OProver-8B-Base / Round1 / Round2 — 8B 各阶段 checkpoint
• m-a-p/OProofs — 1.76M statements / 6.80M proofs / 1.06M trajectories
虽然,OProver当今仍主要围绕Lean 4 whole-proof proving 张开。
后续值得不雅察的是,这种agentic refinement框架能否搬动到Coq、Isabelle以及工程级formal methods用具,以及更长的数据与模子协同进化周期中性能进步会执续多久。
论文:https://arxiv.org/abs/2605.17283
代码:https://github.com/multimodal-art-projection/OProver
模子与数据:https://huggingface.co/collections/m-a-p/oprover手机百家家乐app下载